Beyond Binary Classification: A Semi-supervised Approach to Generalized AI-generated Image Detection
Abstract
The rapid advancement of generators (e.g., StyleGAN, Midjourney, DALL-E) has produced highly realistic synthetic images, posing significant challenges to digital media authenticity. These generators are typically based on a few core architectural families, primarily Generative Adversarial Networks (GANs) and Diffusion Models (DMs). A critical vulnerability in current forensics is the failure of detectors to achieve cross-generator generalization, especially when crossing architectural boundaries (e.g., from GANs to DMs).
We hypothesize that this gap stems from fundamental differences in the artifacts produced by these distinct architectures. In this work, we provide a theoretical analysis explaining how the distinct optimization objectives of GAN and DM architectures lead to different manifold coverage behaviors. We demonstrate that GANs permit partial coverage, often leading to boundary artifacts, while DMs enforce complete coverage, resulting in over-smoothing patterns. Motivated by this analysis, we propose TriDetect (Triarchy Detect), a semi-supervised approach that enhances binary classification by discovering latent architectural patterns within the "fake" class.
Motivation
Current deepfake detectors treat all AI-generated images as a single "fake" class. But generators based on different architectures produce fundamentally different artifacts:
Boundary Artifacts from Partial Coverage
GANs minimize the Jensen-Shannon divergence $D_{JS}(p_{data} \| p_{GAN})$, which remains finite even when $S_{GAN} \subset S_{data}$. This permits partial manifold coverage, leading to characteristic boundary artifacts at the edges of the generated distribution.
Over-smoothing from Complete Coverage
DMs minimize the KL divergence $D_{KL}(p_{data} \| p_{DM})$, which diverges to infinity if $p_{DM}(x) = 0$ anywhere where $p_{data}(x) > 0$. This forces DMs to achieve complete manifold coverage, resulting in over-smoothing patterns as they spread probability mass across the entire data support.
Key Insight: The cross-generator generalization gap stems from fundamentally different optimization objectives. GANs and DMs produce structurally different artifacts. By discovering these latent architectural patterns within the "fake" class, detectors can learn to generalize across unseen generators from the same architectural family.
Theoretical Foundation
Different Optimization, Different Artifacts
We prove two key theorems establishing the theoretical basis for why GANs and DMs produce different artifacts:
Distinct Optimization Objectives
GANs minimize $D_{JS}(p_{data} \| p_{GAN})$ while DMs minimize $D_{KL}(p_{data} \| p_{DM})$. These fundamentally different divergence measures lead to different convergence behaviors and artifact patterns.
Different Manifold Coverage
JS divergence remains finite for partial coverage ($S_{GAN} \subset S_{data}$), while KL divergence diverges to infinity if DM support is incomplete. Consequently, GANs can achieve optimal solutions with partial coverage, while DMs must cover the entire data manifold.
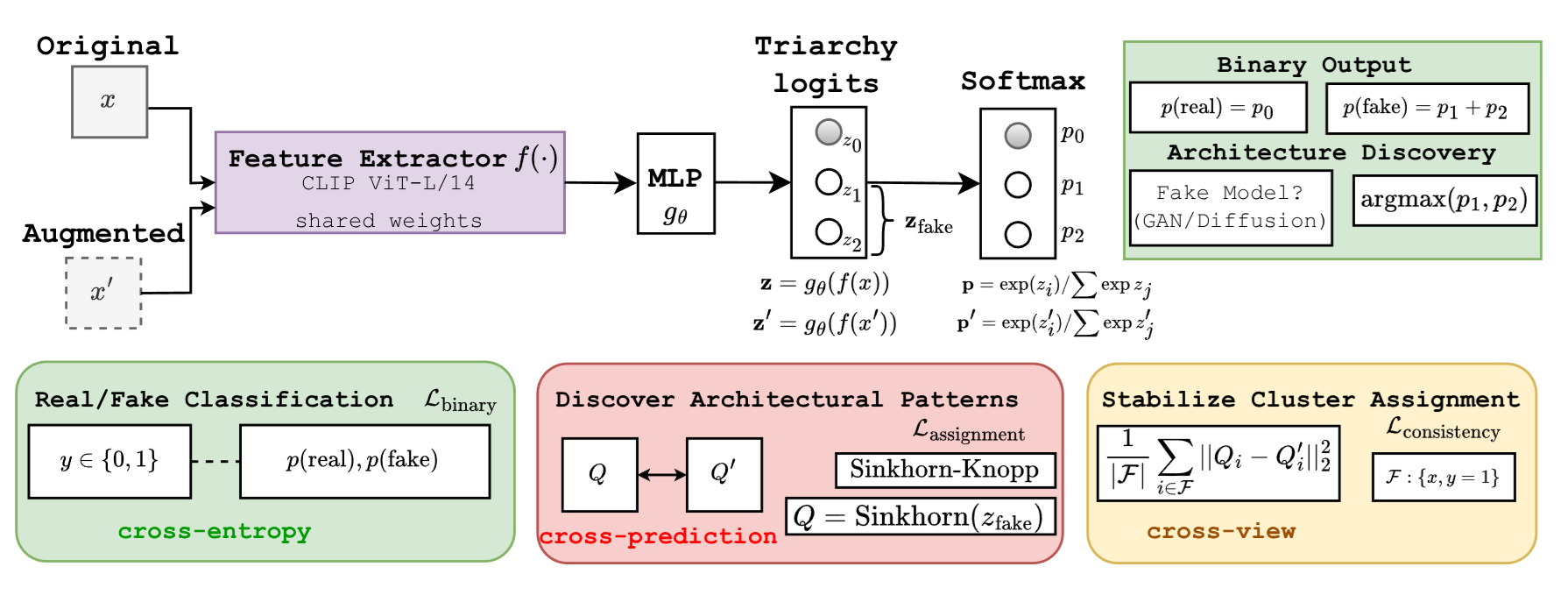
TriDetect Framework
TriDetect employs a semi-supervised approach that goes beyond binary real/fake classification by discovering latent architectural subcategories within the fake class:
Balanced Cluster Assignment via Sinkhorn-Knopp
Instead of treating all fake images uniformly, TriDetect discovers latent clusters within the fake class that correspond to different generator architectures. The Sinkhorn-Knopp algorithm ensures balanced cluster assignments, preventing degenerate solutions where all samples collapse into a single cluster.
Cross-view Consistency
TriDetect enforces consistency between different augmented views of the same image, encouraging the model to learn robust architectural fingerprints rather than superficial image-level features. This cross-view mechanism ensures that the discovered clusters capture fundamental generation-process distinctions.
Triarchy Classification
The framework establishes a three-way classification: Real, GAN-generated, and DM-generated. By learning to distinguish these architectural families during training, the model generalizes to unseen generators from the same family at test time.
Main Results
TriDetect is evaluated on two standard benchmarks and three in-the-wild datasets against 13 baselines.
Comparison on AIGCDetectBenchmark (ACC)
Accuracy across 16 generators spanning both GANs and diffusion models:
| Method | CycleGAN | ProGAN | BigGAN | ADM | Wukong | Glide | MidJourney | DALLE2 | Avg |
|---|---|---|---|---|---|---|---|---|---|
| CNNSpot | 0.4974 | 0.4975 | 0.4858 | 0.5170 | 0.9658 | 0.5882 | 0.5344 | 0.5810 | 0.6059 |
| FreDect | 0.5049 | 0.5405 | 0.7083 | 0.5368 | 0.9443 | 0.5533 | 0.5473 | 0.5530 | 0.6434 |
| CORE | 0.5061 | 0.5083 | 0.5063 | 0.5684 | 0.9643 | 0.9498 | 0.5298 | 0.5920 | 0.6441 |
| UnivFD | 0.8812 | 0.7349 | 0.8273 | 0.7212 | 0.8469 | 0.9482 | 0.7583 | 0.8715 | 0.8299 |
| NPR | 0.7354 | 0.8986 | 0.6993 | 0.7745 | 0.9177 | 0.9751 | 0.7748 | 0.9635 | 0.8472 |
| Effort | 0.9387 | 0.9020 | 0.9863 | 0.5872 | 0.9878 | 0.7942 | 0.7411 | 0.7525 | 0.8804 |
| TriDetect | 0.9974 | 0.9909 | 0.9760 | 0.7482 | 0.9963 | 0.9488 | 0.7480 | 0.9405 | 0.9152 |
Comparison on WildFake (AUC)
AUC performance on the in-the-wild WildFake dataset across 10 generators:
| Method | DALL-E | DDIM | DDPM | VQDM | BigGAN | StarGAN | StyleGAN | DF-GAN | GALIP | GigaGAN | Avg |
|---|---|---|---|---|---|---|---|---|---|---|---|
| CNNSpot | 0.8220 | 0.5943 | 0.3375 | 0.3706 | 0.9513 | 0.5003 | 0.4613 | 0.5304 | 0.5143 | 0.4285 | 0.5511 |
| CORE | 0.9213 | 0.7088 | 0.5795 | 0.8723 | 0.9224 | 0.7298 | 0.5879 | 0.9104 | 0.7876 | 0.7192 | 0.7739 |
| UnivFD | 0.5857 | 0.8008 | 0.7873 | 0.7802 | 0.8711 | 0.8779 | 0.6156 | 0.9597 | 0.9257 | 0.8417 | 0.8046 |
| NPR | 0.8056 | 0.9063 | 0.7906 | 0.9339 | 0.9128 | 0.8022 | 0.5161 | 0.9233 | 0.7018 | 0.8276 | 0.8120 |
| Effort | 0.8537 | 0.8486 | 0.7197 | 0.9372 | 0.9599 | 0.9023 | 0.7605 | 0.9994 | 0.9343 | 0.9013 | 0.8817 |
| TriDetect | 0.9189 | 0.8823 | 0.7106 | 0.9787 | 0.9802 | 1.0000 | 0.7245 | 1.0000 | 0.9774 | 0.9981 | 0.9171 |
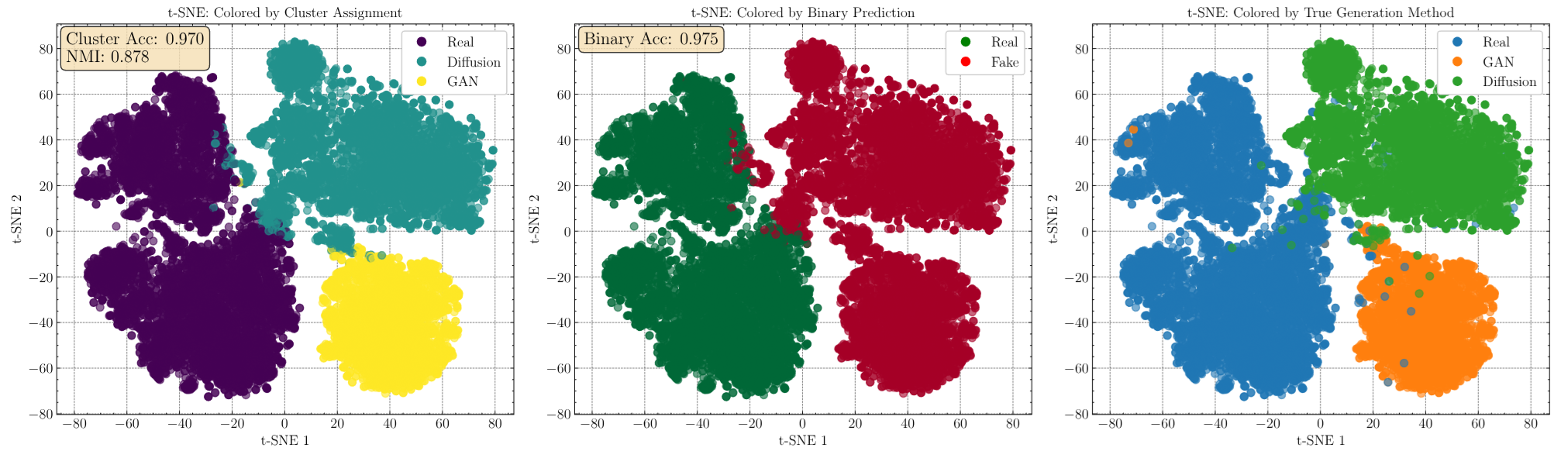
Key Findings
Superior Cross-generator Generalization
TriDetect significantly outperforms all 13 baselines on average across both benchmarks, particularly when crossing architectural boundaries (e.g., trained on GANs, tested on DMs like ADM, Wukong, VQDM).
Effective on In-the-wild Data
On the WildFake dataset, TriDetect achieves perfect or near-perfect detection on several generators (StarGAN: 1.0, DF-GAN: 1.0, GigaGAN: 0.998) where many baselines fail.
Theoretically Grounded
The empirical results validate the theoretical analysis: detectors that learn to distinguish GAN vs DM artifacts achieve better generalization than those treating all fakes uniformly.
Citation
If you find this work useful in your research, please consider citing:
@inproceedings{nguyenle2026tridetect,
title = {Beyond Binary Classification: A Semi-supervised
Approach to Generalized AI-generated Image
Detection},
author = {Nguyen-Le, Hong-Hanh and Tran, Van-Tuan
and Nguyen, Dinh-Thuc and Le-Khac, Nhien-An},
booktitle = {Proceedings of the AAAI Conference on
Artificial Intelligence (AAAI-26)},
year = {2026}
} Acknowledgments
This publication has emanated from research conducted with the financial support of Science Foundation Ireland under Grant number 18/CRT/6183.