ToFU: Transforming How Federated Learning Systems Forget User Data
Abstract
Neural networks unintentionally memorize training data, creating privacy risks in federated learning (FL) systems, such as inference and reconstruction attacks on sensitive data. To mitigate these risks and to comply with privacy regulations, Federated Unlearning (FU) has been introduced to enable participants in FL systems to remove their data's influence from the global model. However, current FU methods primarily act post-hoc, struggling to efficiently erase information deeply memorized by neural networks.
We argue that effective unlearning necessitates a paradigm shift: designing FL systems inherently amenable to forgetting. To this end, we propose ToFU (Transformation-guided Federated Unlearning), a learning-to-unlearn framework that incorporates transformations during the learning process to reduce memorization of specific instances. Our theoretical analysis reveals how transformation composition provably bounds instance-specific information, directly simplifying subsequent unlearning. Crucially, ToFU can work as a plug-and-play framework that improves the performance of existing FU methods.
Motivation
With regulations like GDPR and CCPA mandating the "right to be forgotten," FL systems must incorporate mechanisms for removing a participant's data influence from the global model. However, current approaches face fundamental challenges:
Post-hoc Approaches Are Insufficient
Current FU methods modify model architectures or parameters after training to achieve unlearning, overlooking the fundamental relationship between how models learn and how effectively they can unlearn.
Deep Memorization
Neural networks memorize specific training instances, making it difficult to fully erase their influence. The deeper the memorization, the harder the unlearning.
Federated Constraints
Data remains distributed across clients, communication bandwidth is limited, the server cannot access client data, and client knowledge permeates throughout the global model.
Paradigm Shift: Instead of treating unlearning as a post-hoc operation, ToFU designs the learning process itself to be inherently amenable to forgetting — by training on transformed samples rather than raw data, the model learns task-relevant features without memorizing specific instances.
Theoretical Foundation
Unlearning as Mutual Information Minimization
We formulate the unlearning challenge as an optimization problem: given a trained model $\theta$ and a forget set $D_{forget}$, find $\theta'$ such that mutual information $I(\theta, \theta'; D_{forget})$ is minimized while $I(\theta, \theta'; D_{retain})$ is maximized.
Transformation Composition Theorem
We prove that composing multiple transformations progressively reduces the mutual information between the model and forgetting samples. For any two transformations $\mathcal{T}_1$ and $\mathcal{T}_2$:
$$I(\theta, \mathcal{T}_1 \circ \mathcal{T}_2; D_{forget}) \leq I(\theta, \mathcal{T}_1; D_{forget})$$
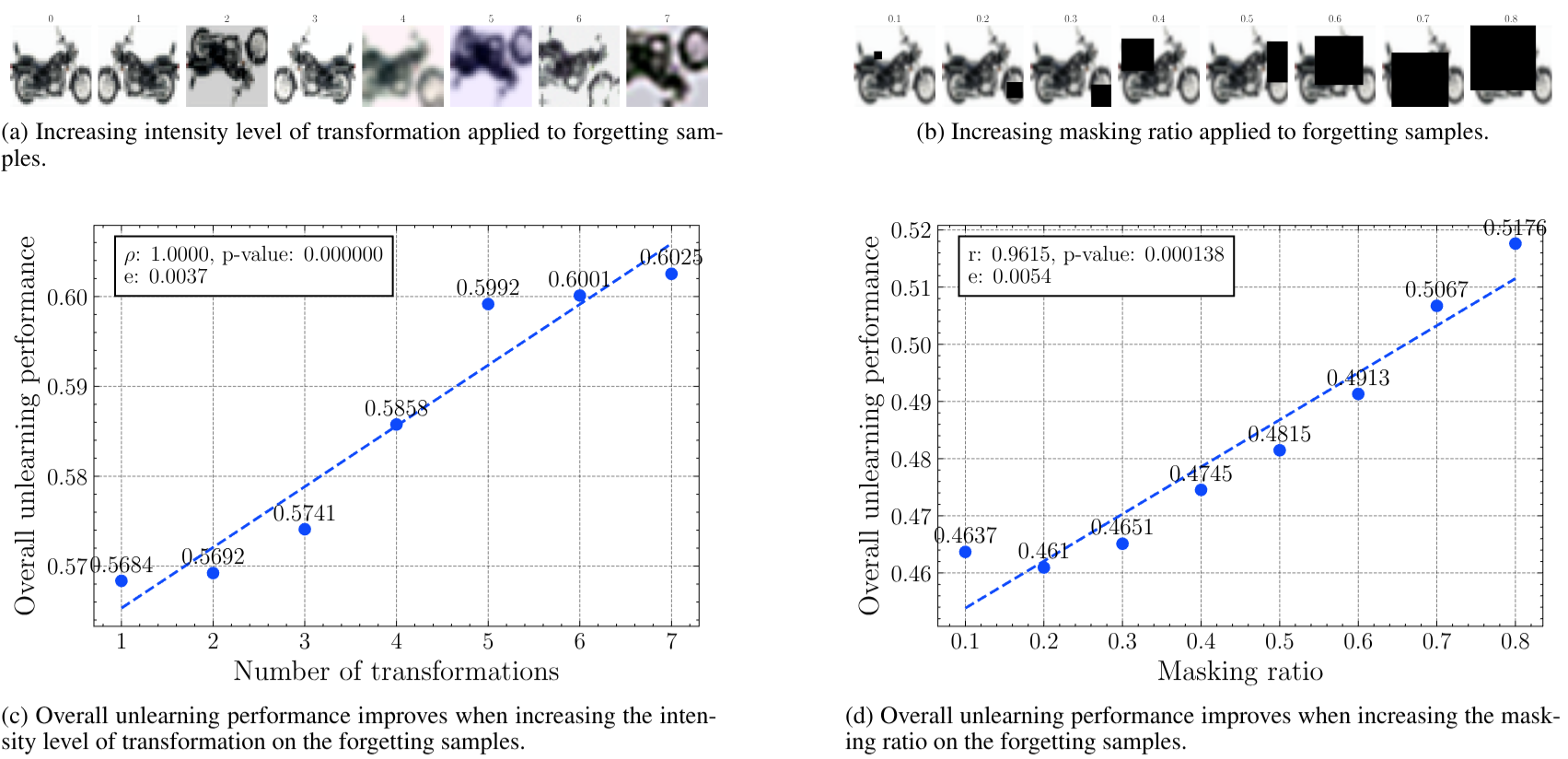
This extends to any number of transformations: increasing the intensity level of transformation monotonically improves unlearning performance with respect to the forget set.
ToFU Framework
ToFU integrates three key components into the federated learning process:
Sample-dependent Transformation Strategy
An inverse quantile value function dynamically determines the transformation intensity for each sample based on its loss: samples with lower loss (already well-learned) receive more transformations, while harder samples receive fewer. The maximum intensity $M$ increases linearly throughout training.
Transformation-invariant Regularization
A KL divergence term between representations of transformed and original data encourages the model to learn consistent features across different transformations of the same sample, rather than memorizing instance-specific characteristics.
Lightweight Unlearning Procedure
When a removal request is issued, unlearning reduces to a simple fine-tuning stage on the retain set. Because the model already learned transformation-invariant features (not instance-specific ones), forgetting is straightforward.
Loss Function
The training loss combines a task loss with the transformation-invariant regularizer:
$$\ell(\theta; x, y) = \underbrace{-y\log(p_\theta(x^*))}_{\text{Task loss}} + \gamma \underbrace{D_{KL}(f_\theta(x^*) \parallel f_\theta(x))}_{\text{Transformation-invariant reg.}}$$
where $x^* = \mathcal{T}(x)$ is the transformed sample and $\gamma = 0.01$ controls the regularization strength.
Main Results
Comparison with Federated Unlearning Baselines
| Dataset | Method | Test Acc | Retain Acc | MIA Efficacy | Overall |
|---|---|---|---|---|---|
| CIFAR-10 | |||||
| FedEraser | 0.7685 | 0.8739 | 0.2926 | 0.6450 | |
| FedPGD | 0.7826 | 0.8959 | 0.2910 | 0.6565 | |
| FedAda | 0.7755 | 0.8754 | 0.2891 | 0.6466 | |
| ToFU | 0.7943 | 0.8955 | 0.3239 | 0.6712 | |
| CIFAR-100 | |||||
| FedEraser | 0.4764 | 0.7425 | 0.2949 | 0.5046 | |
| FedPGD | 0.4682 | 0.6659 | 0.2221 | 0.4520 | |
| FedAda | 0.4803 | 0.6920 | 0.3629 | 0.5117 | |
| ToFU | 0.5032 | 0.7802 | 0.4560 | 0.5798 | |
| MUFAC | |||||
| FedEraser | 0.8597 | 0.8900 | 0.3586 | 0.7027 | |
| FedPGD | 0.8431 | 0.8776 | 0.3757 | 0.6988 | |
| FedAda | 0.7600 | 0.8158 | 0.3934 | 0.6564 | |
| ToFU | 0.8943 | 0.9379 | 0.4651 | 0.7657 | |
Key Advantages
Reduced Memorization
ToFU forces models to learn transformation-invariant features, substantially reducing the model's ability to memorize sample-specific information.
Plug-and-Play Compatibility
ToFU can be integrated with existing FU methods (FedEraser, FedPGD, FedAda) to significantly enhance their performance without modifying their core algorithms.
Reduced Unlearning Time
By incorporating inherent unlearning capabilities into the learning process, ToFU simplifies the unlearning process to a lightweight fine-tuning operation, reducing computational overhead and waiting time for non-unlearning clients.
Citation
If you find this work useful in your research, please consider citing:
@inproceedings{tran2025tofu,
title = {ToFU: Transforming How Federated Learning
Systems Forget User Data},
author = {Tran, Van-Tuan and Nguyen-Le, Hong-Hanh
and Pham, Quoc-Viet},
booktitle = {28th European Conference on Artificial
Intelligence (ECAI-25)},
year = {2025}
} Acknowledgments
This publication has emanated from research conducted with the financial support of Science Foundation Ireland under Grant number 18/CRT/6183.