T²A: Think Twice before Adaptation for DeepFake Detection

Abstract
Deepfake detectors face significant challenges when deployed in real-world environments, particularly when encountering test samples that deviate from training data through postprocessing manipulations or distribution shifts. We demonstrate that postprocessing techniques can completely obscure generation artifacts present in deepfake samples, leading to severe performance degradation.
To address these challenges, we propose T²A (Think Twice before Adaptation), a novel online test-time adaptation method that enhances detector adaptability during inference — without requiring access to source training data or labels. Our key idea enables the model to explore alternative options through Uncertainty-aware Negative Learning rather than solely relying on initial predictions. We also introduce Uncertain Sample Prioritization and Gradients Masking to improve adaptation efficiency. Empirically, T²A achieves state-of-the-art results across multiple benchmarks.
Problem Definition
While deepfake detectors perform well in controlled settings, real-world deployment introduces two critical challenges that break their assumptions:
Why adapt at inference time?
First, adversaries can apply unknown postprocessing techniques, such as compression, resizing, blurring, color manipulation, which destroy the subtle generation artifacts detectors rely on. Second, test samples often come from distributions that differ substantially from training data, causing performance degradation. Retraining with new labeled data is costly and impractical when distribution shifts are continuous or unknown.
T²A addresses this by performing online test-time adaptation: adapting the detector on-the-fly using only the unlabeled test stream, with no access to the original training data or labels. We formalize two evaluation scenarios:
Unseen Postprocessing Techniques
The test distribution matches training, but samples undergo unknown postprocessing operations (blur, compression, color shifts) that obscure generation artifacts.
Unseen Distribution + Postprocessing
Test samples come from an entirely different data distribution and are subjected to unknown postprocessing — the most challenging real-world setting.
Uncertainty-aware Negative Learning
Existing TTA methods rely on Entropy Minimization (EM), which pushes the model toward its most confident prediction. But in deepfake detection, this causes two failure modes: confirmation bias (reinforcing incorrect confident predictions) and model collapse (predicting all samples as the same class).
Core Insight: Instead of blindly trusting initial predictions, T²A enables the model to think twice — exploring alternative options through negative learning with noisy pseudo-labels before committing to a decision.
T²A consists of three complementary components:
Uncertainty-aware Negative Learning (UNL)
Rather than pushing toward the most confident class, negative learning steers the model away from unlikely classes. We model pseudo-label uncertainty via Bernoulli noise flipping: confident predictions are rarely flipped, while uncertain ones are flipped more often. A noise-tolerant negative loss combines normalized negative loss with a passive loss function to handle noisy gradients robustly.
Uncertain Sample Prioritization (USP)
Not all test samples contribute equally to adaptation. USP incorporates Focal Loss to dynamically down-weight high-confidence samples and prioritize uncertain ones — making each parameter update more efficient and informative.
Gradients Masking (GM)
To prevent catastrophic adaptation, we selectively mask gradients during backpropagation. Only parameters whose gradients align with BatchNorm layer gradients (measured via cosine similarity) are updated — preserving core detection capabilities while expanding adaptation capacity beyond BN-only approaches.
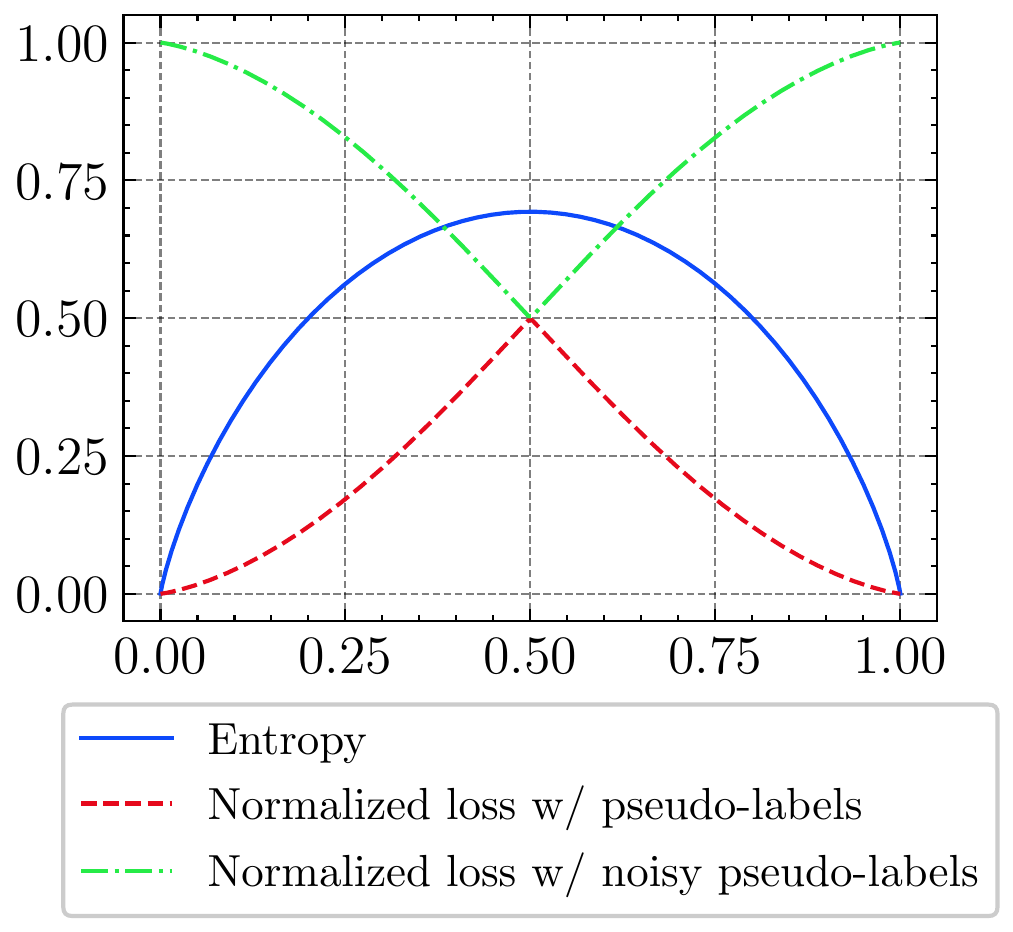
(a) Normalized loss with pseudo label $\mathcal{L}_{norm}(x, \hat{y})$ and noisy pseudo-label $\mathcal{L}_{nn}(x,\tilde{y})$. $\mathcal{L}_{nn}(x,\tilde{y})$ is the opposite of $\mathcal{L}_{norm}(x, \hat{y})$.
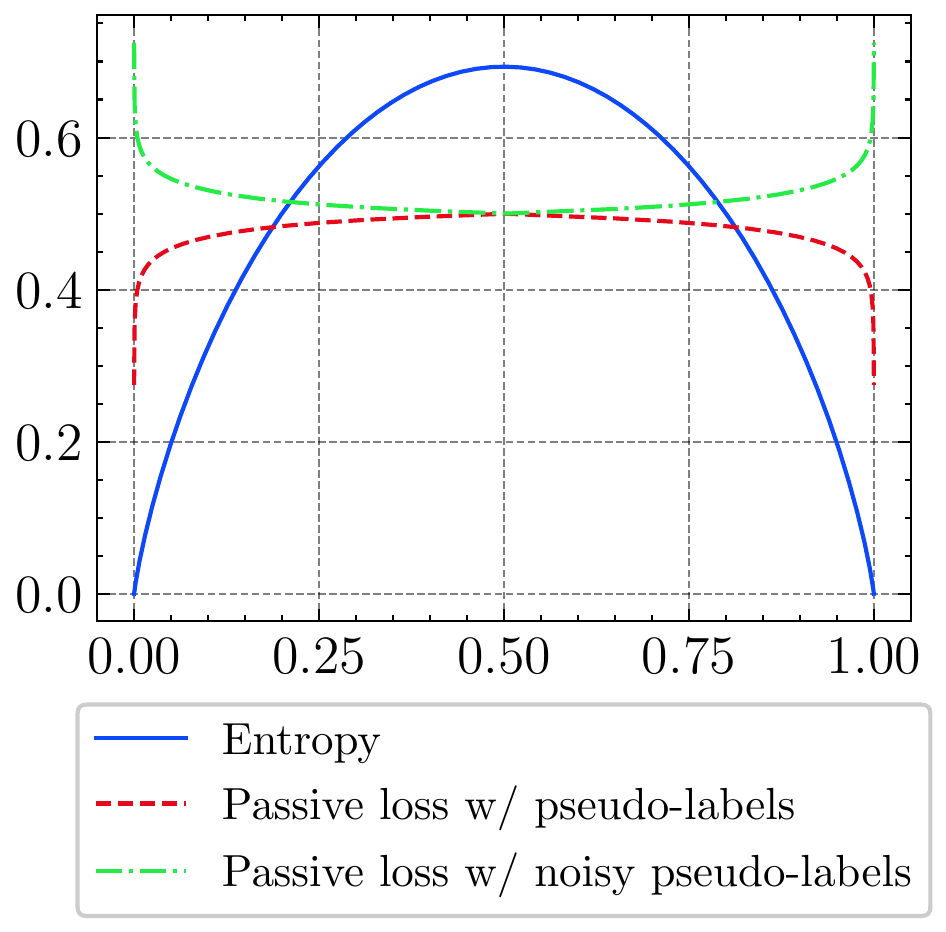
(b) Passive loss function with pseudo label $\mathcal{L}_{p}(x, \hat{y})$ and noisy pseudo-label $\mathcal{L}_{p}(x,\tilde{y})$. $\mathcal{L}_{p}(x,\tilde{y})$ is the opposite of $\mathcal{L}_{p}(x, \hat{y})$.
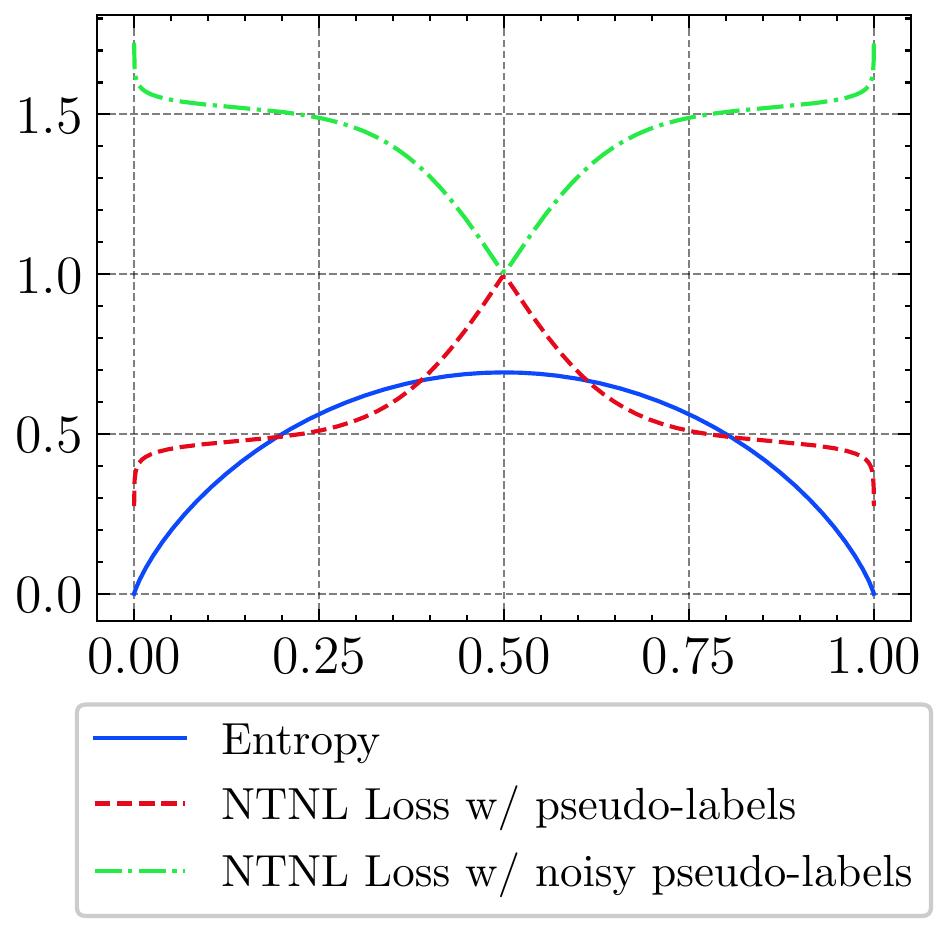
(c) Noise-tolerant negative loss (NTNL) functions with pseudo label $\mathcal{L}_{NTNL}(x, \hat{y})$ and noisy-pseudo label $\mathcal{L}_{NTNL}(x,\tilde{y})$. $\mathcal{L}_{NTNL}(x,\tilde{y})$ is the opposite of $\mathcal{L}_{NTNL}(x, \hat{y})$.
Main Results
We evaluate T²A under both scenarios using Xception trained on FaceForensics++ as the source model, comparing against seven state-of-the-art TTA methods and four deepfake detectors.
| Method | Color Contrast | Color Saturation | Resize | Gaussian Blur | Average | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ACC | AUC | AP | ACC | AUC | AP | ACC | AUC | AP | ACC | AUC | AP | ACC | AUC | AP | |
| Source | .789 | .870 | .964 | .807 | .820 | .943 | .812 | .877 | .967 | .843 | .842 | .952 | .813 | .852 | .957 |
| TENT | .875 | .904 | .973 | .841 | .851 | .956 | .852 | .884 | .968 | .862 | .884 | .968 | .857 | .881 | .966 |
| MEMO | .829 | .861 | .960 | .827 | .824 | .948 | .835 | .861 | .962 | .833 | .868 | .963 | .831 | .854 | .958 |
| EATA | .874 | .904 | .973 | .840 | .851 | .956 | .851 | .884 | .968 | .863 | .885 | .968 | .857 | .881 | .966 |
| CoTTA | .855 | .871 | .960 | .821 | .826 | .948 | .845 | .862 | .962 | .852 | .866 | .962 | .843 | .856 | .958 |
| LAME | .788 | .819 | .939 | .809 | .759 | .910 | .796 | .811 | .931 | .807 | .752 | .904 | .800 | .785 | .921 |
| VIDA | .852 | .879 | .965 | .817 | .821 | .945 | .839 | .867 | .962 | .845 | .863 | .960 | .838 | .858 | .958 |
| COME | .866 | .898 | .972 | .839 | .850 | .957 | .853 | .878 | .965 | .862 | .881 | .967 | .855 | .877 | .965 |
| T²A (Ours) | .875 | .904 | .973 | .844 | .852 | .957 | .850 | .884 | .968 | .864 | .885 | .968 | .858 | .881 | .966 |
| Method | CelebDF-v1 | CelebDF-v2 | DFD | FSh | DFDCP | UADFV | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ACC | AUC | AP | ACC | AUC | AP | ACC | AUC | AP | ACC | AUC | AP | ACC | AUC | AP | ACC | AUC | AP | |
| Source | .617 | .573 | .680 | .662 | .612 | .734 | .834 | .557 | .889 | .537 | .559 | .548 | .674 | .655 | .760 | .632 | .711 | .644 |
| TENT | .633 | .617 | .703 | .637 | .633 | .748 | .763 | .641 | .926 | .529 | .559 | .554 | .721 | .699 | .776 | .663 | .733 | .667 |
| MEMO | .646 | .622 | .700 | .668 | .594 | .717 | .880 | .588 | .915 | .511 | .562 | .541 | .700 | .689 | .747 | .634 | .730 | .665 |
| EATA | .631 | .617 | .703 | .639 | .633 | .747 | .758 | .644 | .928 | .531 | .558 | .553 | .725 | .700 | .776 | .660 | .733 | .669 |
| CoTTA | .635 | .628 | .698 | .660 | .619 | .738 | .876 | .607 | .922 | .529 | .566 | .553 | .693 | .652 | .738 | .632 | .721 | .653 |
| LAME | .621 | .590 | .673 | .651 | .591 | .703 | .894 | .572 | .909 | .501 | .531 | .517 | .648 | .599 | .700 | .510 | .676 | .628 |
| VIDA | .637 | .606 | .668 | .676 | .559 | .685 | .881 | .595 | .923 | .519 | .529 | .534 | .677 | .693 | .769 | .609 | .697 | .615 |
| COME | .633 | .616 | .704 | .639 | .633 | .747 | .757 | .645 | .929 | .529 | .559 | .554 | .726 | .701 | .776 | .663 | .732 | .667 |
| T²A (Ours) | .670 | .675 | .730 | .672 | .643 | .757 | .759 | .644 | .928 | .537 | .573 | .566 | .733 | .732 | .777 | .683 | .762 | .712 |
| Method | Color Contrast | Color Saturation | Resize | Gaussian Blur | Average | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ACC | AUC | AP | ACC | AUC | AP | ACC | AUC | AP | ACC | AUC | AP | ACC | AUC | AP | |
| CORE | .815 | .825 | .935 | .824 | .807 | .940 | .836 | .863 | .960 | .833 | .827 | .941 | .827 | .830 | .944 |
| CORE + T²A | .861 | .874 | .960 | .841 | .850 | .945 | .843 | .890 | .951 | .849 | .866 | .954 | .849 | .873 | .953 |
| Effi.B4 | .698 | .846 | .953 | .849 | .797 | .926 | .831 | .846 | .953 | .838 | .793 | .929 | .804 | .821 | .940 |
| Effi.B4 + T²A | .853 | .864 | .954 | .827 | .831 | .937 | .830 | .836 | .949 | .844 | .867 | .952 | .838 | .859 | .948 |
| F3Net | .804 | .831 | .944 | .854 | .820 | .941 | .855 | .868 | .958 | .836 | .814 | .937 | .828 | .839 | .949 |
| F3Net + T²A | .861 | .888 | .964 | .862 | .874 | .960 | .814 | .872 | .963 | .842 | .849 | .952 | .855 | .878 | .962 |
| RECCE | .808 | .819 | .939 | .835 | .792 | .928 | .814 | .834 | .948 | .836 | .814 | .937 | .823 | .814 | .938 |
| RECCE + T²A | .850 | .870 | .959 | .829 | .843 | .941 | .841 | .843 | .950 | .842 | .869 | .952 | .841 | .856 | .950 |
| Method | CelebDF-v1 | CelebDF-v2 | DFD | FSh | DFDCP | UADFV | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ACC | AUC | AP | ACC | AUC | AP | ACC | AUC | AP | ACC | AUC | AP | ACC | AUC | AP | ACC | AUC | AP | |
| CORE | .652 | .683 | .784 | .647 | .627 | .753 | .852 | .532 | .896 | .505 | .522 | .515 | .702 | .647 | .751 | .609 | .748 | .733 |
| CORE + T²A | .656 | .688 | .760 | .716 | .657 | .758 | .795 | .629 | .929 | .520 | .510 | .499 | .672 | .661 | .757 | .634 | .781 | .769 |
| Effi.B4 | .631 | .661 | .720 | .643 | .549 | .656 | .874 | .631 | .928 | .529 | .574 | .550 | .634 | .502 | .644 | .558 | .679 | .636 |
| Effi.B4 + T²A | .642 | .666 | .754 | .635 | .435 | .731 | .826 | .689 | .945 | .545 | .594 | .560 | .648 | .582 | .704 | .615 | .711 | .662 |
| F3Net | .625 | .654 | .761 | .656 | .660 | .768 | .855 | .551 | .901 | .523 | .545 | .564 | .669 | .653 | .744 | .584 | .715 | .687 |
| F3Net + T²A | .652 | .666 | .753 | .660 | .641 | .728 | .750 | .610 | .924 | .513 | .557 | .565 | .680 | .696 | .783 | .656 | .745 | .688 |
| RECCE | .580 | .569 | .680 | .678 | .618 | .753 | .818 | .626 | .936 | .524 | .537 | .528 | .667 | .636 | .733 | .652 | .719 | .678 |
| RECCE + T²A | .658 | .651 | .723 | .672 | .673 | .778 | .730 | .652 | .935 | .532 | .551 | .559 | .703 | .718 | .795 | .712 | .791 | .737 |
Citation
If you find this work useful in your research, please consider citing:
@inproceedings{nguyenle2025think,
title = {Think Twice before Adaptation: Improving
Adaptability of DeepFake Detection via
Online Test-Time Adaptation},
author = {Nguyen-Le, Hong-Hanh and Tran, Van-Tuan
and Nguyen, Dinh-Thuc and Le-Khac, Nhien-An},
booktitle = {Proceedings of the Thirty-Fourth International
Joint Conference on Artificial Intelligence
(IJCAI-25)},
year = {2025}
} Acknowledgments
This publication has emanated from research conducted with the financial support of Science Foundation Ireland under Grant number 18/CRT/6183.