Privacy-Preserving Speaker Verification using Ranking-of-Element Hashing
Abstract
The advancements in automatic speaker recognition have led to the exploration of voice data for verification systems. This raises concerns about the security of storing voice templates in plaintext. In this paper, we propose a novel cancellable biometrics that does not require users to manage random matrices or tokens.
First, we pre-process the raw voice data and feed it into a deep feature extraction module to obtain embeddings. Next, we propose a hashing scheme, Ranking-of-Elements (RoE), which generates compact hashed codes by recording the number of elements whose values are lower than that of a random element. This approach captures more information from smaller-valued elements and prevents the adversary from guessing the ranking value through Attacks via Record Multiplicity. Lastly, we introduce a Soft Matching method to mitigate the variations in templates resulting from environmental noise. We evaluate the performance and security of our method on two datasets: TIMIT and VoxCeleb1.
Motivation
Biometric Template Protection (BTP) has gained attention as a promising approach to securing biometric embeddings. Voice-based BTP schemes must meet security properties including irreversibility, unlinkability, and revocability, while maintaining high recognition performance.
Existing methods like Winner-Take-All (WTA) hashing have several limitations:
Sensitivity to High-Value Elements
WTA exclusively concentrates on identifying maximum values within the template. Larger values are more likely to be selected as output, leading to performance degradation and information loss from smaller-value elements.
Vulnerability to Reversion Attacks
The local ranking of each element in the original vector can be vulnerable against reversion attacks, violating security requirements related to revocability and unlinkability.
Dependency on User-Specific Data
State-of-the-art voice-based CB using WTA requires users to manage binary orthogonal matrices, raising practical security and usability limitations.
Large Hashed-Code Size
WTA-based approaches often require a large hashed-code size to preserve accuracy performance, resulting in higher storage complexity.
Core Idea: RoE records the number of elements whose values are lower than that of a randomly selected element — giving every element an equal chance to be selected, eliminating information loss from smaller-valued elements, and preventing the adversary from guessing rankings through record multiplicity attacks.
Proposed System
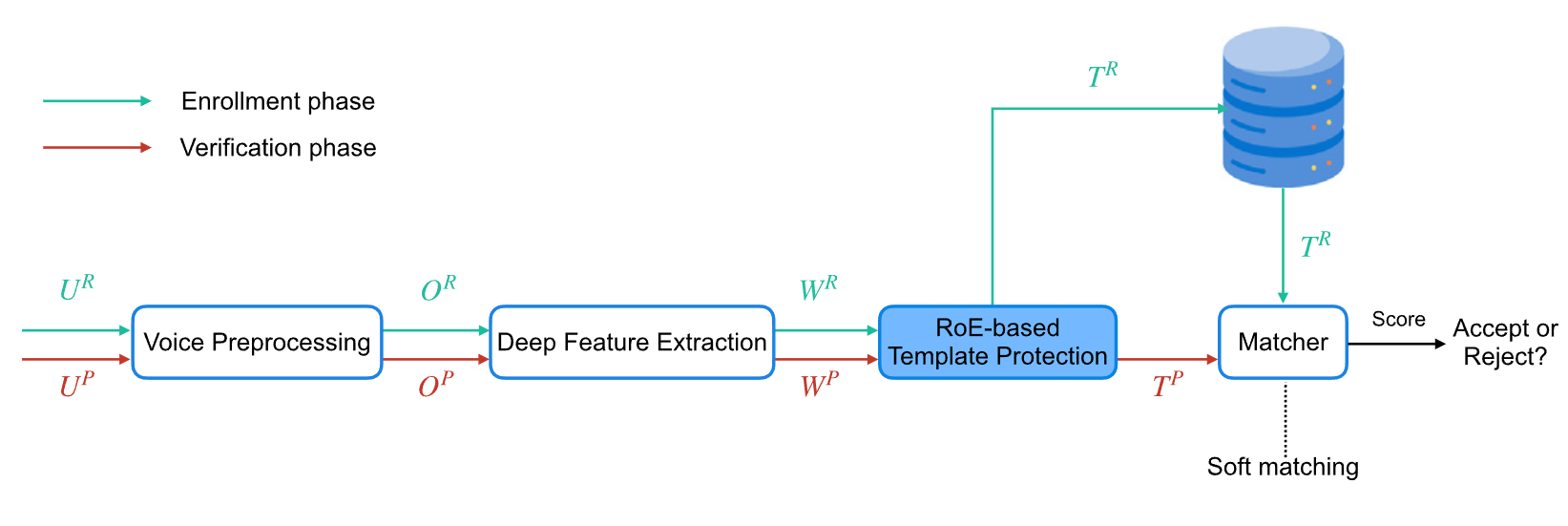
The system comprises three main modules: Voice Processing, Deep Feature Extraction (RawNet3), and RoE-based Template Protection.
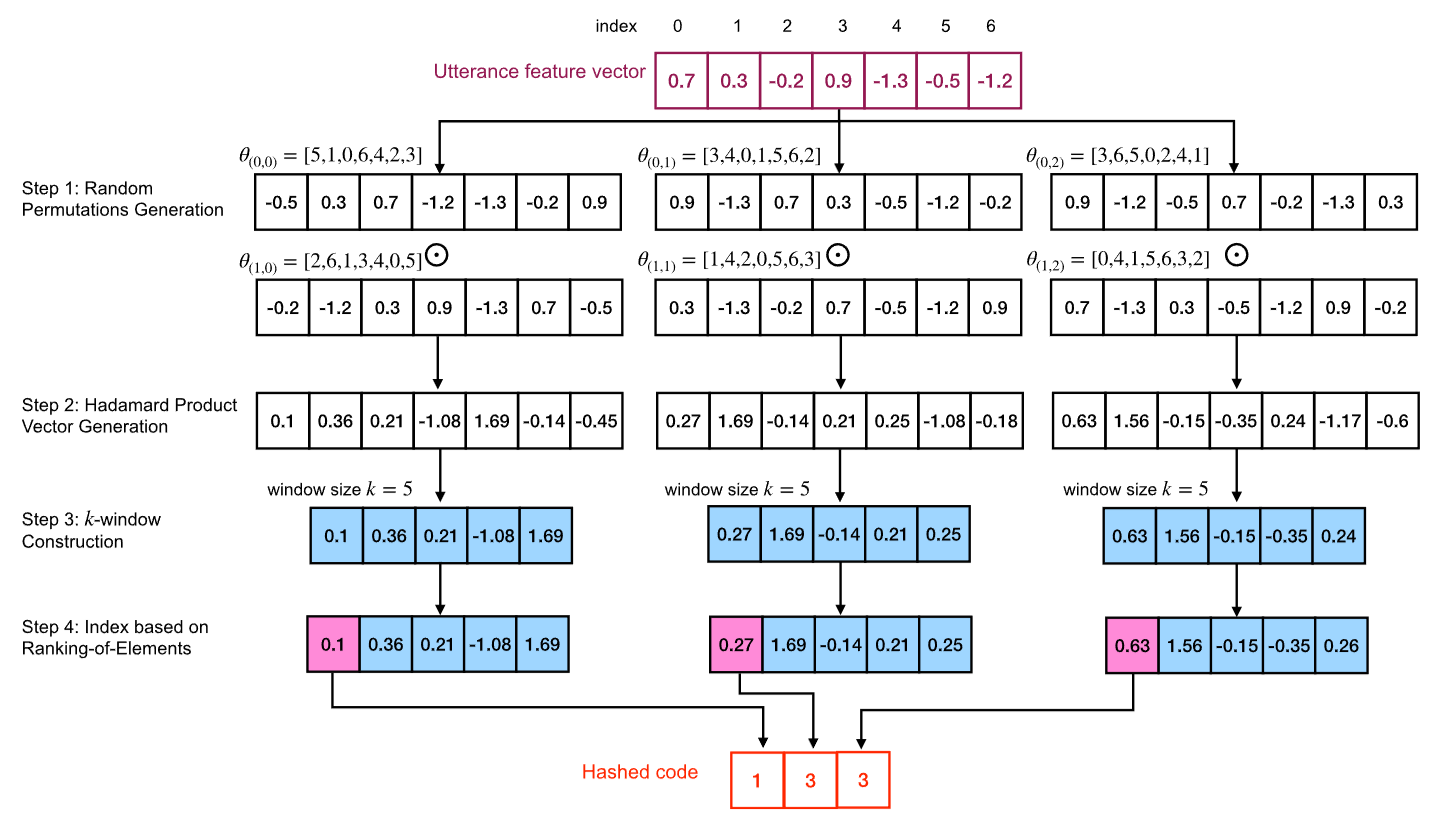
Ranking-of-Elements Hashing
RoE hashing introduces two key modifications to address WTA's limitations:
- Equal selection probability: Instead of emphasizing the index of the largest element, RoE records the number of elements whose values are smaller than that of a selected element. Each element has an equal chance to be the output.
- Random element selection within each window: To prevent the adversary from guessing the ranking value, RoE randomly selects an element within each k-sized window via Attacks via Record Multiplicity (ARM).
Given window size $k$, the RoE algorithm randomly selects an element $a$ within each $k$-sized window and records the count of elements whose values are lower than that of element $a$. This produces hashed codes in the range $[0, k-1]$.
Soft Matching
Environmental factors like microphone quality and channel conditions can cause variations in voice features. The Soft Matching procedure incorporates a threshold t to provide robust tolerance for ranking changes:
$$\text{soft\_matching}(T^R, T^P) = 1 - \frac{\text{sum}(d)}{m}$$
where $d_i$ is softened: if $|d_i| \leq t$, then $d_i = \frac{|d_i|}{t+1}$; otherwise $d_i = 1$. This allows the system to tolerate small differences from environmental factors while still distinguishing between genuine users and impostors.
Main Results
EER Comparison (Recognition Performance)
RoE consistently outperforms WTA and IoM (Index-of-Maximum) across both datasets and all parameter settings.
| Method | VoxCeleb1 | TIMIT | ||||||
|---|---|---|---|---|---|---|---|---|
| k=8 | k=16 | k=32 | k=64 | k=8 | k=16 | k=32 | k=64 | |
| WTA | 7.51 | 6.03 | 5.23 | 3.61 | 5.15 | 4.72 | 2.61 | 1.82 |
| IoM | 4.82 | 3.94 | 3.23 | 2.01 | 3.12 | 2.03 | 1.31 | 0.93 |
| RoE | 4.21 | 3.2 | 1.53 | 1.14 | 2.02 | 1.11 | 0.84 | 0.7 |
TMR Comparison (True Match Rate at FMR=0.1%)
| Method | VoxCeleb1 | TIMIT | ||||||
|---|---|---|---|---|---|---|---|---|
| k=8 | k=16 | k=32 | k=64 | k=8 | k=16 | k=32 | k=64 | |
| WTA | 85.16 | 86.18 | 87.45 | 88.51 | 86.27 | 87.19 | 88.62 | 89.10 |
| IoM | 89.07 | 89.84 | 90.75 | 91.59 | 89.89 | 90.57 | 91.38 | 94.18 |
| RoE | 93.61 | 94.67 | 96.23 | 96.78 | 95.63 | 96.24 | 97.01 | 98.47 |
Impact of Soft Matching
| Method | With Soft Matching | Without Soft Matching | ||
|---|---|---|---|---|
| EER (%) | TMR (%) | EER (%) | TMR (%) | |
| VoxCeleb1 | ||||
| WTA | 1.83 | 90.27 | 9.34 | 79.26 |
| IoM | 1.21 | 92.76 | 8.26 | 81.24 |
| RoE | 0.92 | 97.40 | 7.56 | 85.68 |
| TIMIT | ||||
| WTA | 1.32 | 91.07 | 8.75 | 82.05 |
| IoM | 0.61 | 95.62 | 7.60 | 83.48 |
| RoE | 0.53 | 98.81 | 5.98 | 84.91 |
Security & Privacy Analysis
Extensive security and privacy analyses demonstrate that RoE fulfills the requirements specified in the ISO/IEC 24745 standard:
Irreversibility
Computationally infeasible to reconstruct the original embedding from a protected template. With optimal parameters, a brute-force attack requires $2^{25088}$ attempts for $m = 512$.
Unlinkability
Mated and non-mated score distributions almost overlap, with $D^{sys}_{\leftrightarrow} = 0.045$ on VoxCeleb1 and $D^{sys}_{\leftrightarrow} = 0.0225$ on TIMIT — satisfying the unlinkability requirement.
Revocability
Pseudo-imposter and imposter score distributions completely overlap, indicating newly cancellable voice templates are indistinguishable from old ones.
Resistance to ARM Attacks
Random element selection within each window requires adversaries to collect at least $2^7$ protected templates per individual. Combined with $\binom{256}{128} \approx 2^{252}$ feature component possibilities, the attack is infeasible in practice.
Citation
If you find this work useful in your research, please consider citing:
@article{nguyenle2025roe,
title = {Privacy-preserving speaker verification system
using Ranking-of-Element hashing},
author = {Nguyen-Le, Hong-Hanh and Tran, Lam
and Nguyen, Dinh Song An
and Le-Khac, Nhien-An and Nguyen, Thuc},
journal = {Pattern Recognition},
volume = {159},
pages = {111107},
year = {2025},
publisher = {Elsevier}
} Acknowledgments
This publication has emanated from research conducted with the financial support of Science Foundation Ireland under Grant number 18/CRT/6183. This publication has also been supported by DAC-lab@FIT - Decentralized Applied Cryptography Lab of Faculty Technology, VNU-HCM University of Science.